My OODA loop post is actually one of the most popular on this site. I blame Venkatesh Rao of Ribbonfarm and his Tempo book and John Robb’s Brave New War for introducing me to Boyd’s methodology. Venkatesh focuses on philosophy and management consulting, and Robb focuses on COIN and human social networks. Both are removed from healthcare, but applying Boyd’s principles to medicine: our enemy is disease, perhaps even ourselves.
Consider aerial dogfighting. The human OODA loop is – Observe, Orient, Decide, Act. You want to “get inside your opponent’s OODA loop” and out-think them, knowing their actions before they do, assuring victory. If you know your opponent’s next move, you can anticipate where to shoot and end the conflict decisively. Quoting Sun Tzu in The Art of War:

If you know the enemy and know yourself, you need not fear the result of a hundred battles. If you know yourself but not the enemy, for every victory gained you will also suffer a defeat. If you know neither the enemy nor yourself, you will succumb in every battle.
Focused, directed, lengthy and perhaps exhausting training for a fighter pilot enables them to “know their enemy” and anticipate action in a high-pressure, high-stakes aerial battle. The penalty for failure is severe – loss of the pilot’s life. Physicians prepare similarly – a lengthy and arduous training process in often adverse circumstances. The penalty for failure is also severe – a patient’s death. Given adequate intelligence and innate skill, successful pilots and physicians internalize their decision trees – transforming the OODA loop to a simpler OA loop – Observe and Act. Focused practice allows the Orient and Decide portions of the loop to become automatic and intuitive, almost Zen-like. This is what some people refer to as ‘Flow’ – an effortlessly hyperproductive state where total focus and immersion in a task suspends the perception of the passage of time.
For a radiologist, ‘flow’ is when you sit down at your PACS at 8am, continuously reading cases, making one great diagnosis after another, smiling as the words appear on Powerscribe. You’re killing the cases and you know it. Then your stomach rumbles – probably time for lunch – you look up at the clock and it is 4pm. That’s flow.
Flow is one of the reasons why experienced professionals are highly productive – and a smart manager will try to keep a star employee ‘in the zone’ as much as possible, removing extraneous interruptions, unnecessary low-value tasks, and distractions.
Kahneman defines this as fast type 1 thinking, intuitive and heuristic : quick, easy, and with sufficient experience/training, usually accurate. But type 1 thinking can fail : a complex process masquerades as a simple one, additional important data is undiscovered or ignored, or a novel agent is introduced. In these circumstances type 2 critical thinking is needed : slow, methodological, deductive and logical. But humans err, substituting heuristic thinking for analytical thinking, and we get it wrong.
For the enemy fighter pilot, its the scene in Top Gun where Tom Cruise hits the air brakes to drop behind an attacking Mig to deliver a kill shot with his last missile. For a physician, it is an uncommon or rare disease presenting like a common one, resulting in a missed diagnosis and lawsuit.
To those experimenting in deep learning and Artificial intelligence, the time to train or teach the network far exceeds the time needed to process an unknown through the trained network. Training can take hours to days, evaluation takes seconds.
Narrow AI’s like Convolutional Neural Networks take advantage of their speed to go through the OODA loop quickly, in a process called inference. I suggest a deep learning algorithm functions as an OA loop on the specific type of data it has been trained on. Inference is quick.
I believe that OODA loops are Kahneman’s Type 2 slow thinking. OA loops are Kahneman’s Type 1 fast thinking. Narrow AI inference is a type 1 OA loop. An AI version of type 2 slow thinking doesn’t yet exist.*
And like humans, Narrow AI can be fooled.

If you haven’t seen the Chihuahua vs. blueberry muffin clickbait picture, consider yourself sheltered. Claims that narrow AI can’t tell the difference are largely, but not entirely, bogus. While Narrow AI is generally faster than people, and potentially more accurate, it can still make errors. But so can people. In general, classification errors can be reduced by creating a more powerful, or ‘deeper’ network. I think collectively we have yet to decide how much error to tolerate in our AI’s. If we are willing to tolerate an error of 5% in humans, are we willing to tolerate the same in our AI’s, or do we expect 97.5%? Or 99%? Or 99.9%?
The single pixel attack is a bit more interesting. While similar images such as the ones above probably won’t pass careful human scrutiny, and frankly adversarial images unrecognizable to humans can be misinterpreted by a classifier:
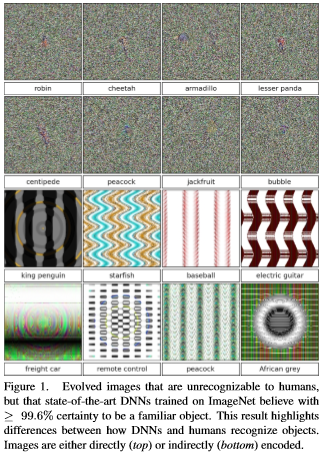
Selecting and perturbing a single pixel is much more subtle, and probably could escape human scrutiny. Jaiwei Su et al address this in their “One Pixel Attack” paper, where the modification of one pixel in an image had between a 66% to 73% chance of changing the classification of that image. By changing more than one pixel, success rates respectively rose. The paper used older, less deep Narrow AI’s like VGG-16 and Network-in-network. Newer models such as DenseNets and ResNets might be harder to fool. This type of “attack” represents a real-world situation where the OA loop fails to account for unexpected new (or perturbed) information, and is incorrect.
Contemporaneous update: Google has developed images that use an adversarial attack to uniformly defeat classification attempts by standard CNN models. By making “stickers” out of these processed images, the presence of such an image, even at less than 20% of the image size, is sufficient to change the classification to what the ensemble dictates, rather than the primary object in an image. They look like this:

I am not aware of defined solutions to these problems – the obvious images that fool the classifier can probably be dealt with by ensembling other, more traditional forms of computer vision image analysis such as HOG or SVM’s. For a one-pixel attack, perhaps widening the network and increasing the number of training samples by either data augmentation or adversarially generated features might make the network more robust. This probably falls into the “too soon to tell” category.
There has been a great deal of interest and emphasis placed lately on understanding black-box models. I’ve written about some of these techniques in other posts. Some investigators feel this is less relevant. However, by understanding how the models fail, they can be strengthened. I’ve also written about this, but from a management standpoint. There is a trade off between accuracy at speed, robustness, and serendipity. I think the same principle applies to our AI’s as well. By understanding the frailty of speedy accuracy vs. redundancies that come at the expense of cost, speed, and sometimes accuracy, we can build systems and processes that not only work but are less likely to fail in unexpected & spectacular ways.
Let’s acknowledge the likelihood of failure of narrow AI where it is most likely to fail, and design our healthcare systems and processes around that, as we begin to incorporate AI into our practice and management. If we do that, we will truly get inside the OODA loop of our opponent – disease – and eradicate it before it even had a chance. What a world to live in where the only thing disease can say is, “I never saw it coming.”
*I believe OODA loops have mathematical analogues. The OODA loop is inherently Bayesian – next actions iteratively decided by prior probabilities. Iterative deep learning constructs include LSTM and RNN’s (Recurrent Neural Networks) and of course, General Adversarial Networks (GANs). There have been attempts to not only use Bayesian learning for hyperparameter optimization but also combining it with RL(Reinforcement Learning) & GANs. Time will only tell if this brings us closer to the vaunted AGI (Artificial General Intelligence)**.
**While I don’t think we will soon solve the AGI question, I wouldn’t be surprised if complex combinations of these methods, along with ones not yet invented, bring us close to top human expert performance in a Narrow AI. But I also suspect that once we start coding creativity and resilience into these algorithms, we will take a hit in accuracy as we approach less narrow forms of AI. We will ultimately solve for the best performance of these systems, and while it may even eventually exceed human ability, there will likely always be an error present. And in that area of error is where future medicine will advance.
© 2018