This a somewhat challenging post with cross-discipline correlations, some unfamiliar terminology, and concepts. There is a payoff!
You can recap part 1 and part 2 here.
The crux of this discussion is time. Understanding the progression towards shorter and shorter time frames on Wall Street enables us to draw parallels and differences in medical care delivery particularly pertaining to processes and data analytics. This is relevant because some vendors tout real-time capabilities in health care data analysis. Possibly not as useful as one thinks.
In trading, the best profit one is a risk-less one. A profit that occurs by simply being present, is reliable, and reproducible, and exposes the trader to no risk. Meet arbitrage. Years ago, it was possible for the same security to be trading at different prices on different exchanges as there was no central marketplace. A network of traders could execute a buy of a stock for $10 in New York, and then sell those same shares on the Los Angeles exchange for $11. If one imagines a 1000 share transaction, a $1 profit per share yields $1000. It was made by the head trader holding up two phones to his head and saying ‘buy’ into one and ’sell’ into the other.* These relationships could be exploited over longer periods of time and represented an information deficit. However, as more traders learned of them, the opportunities became harder to find as greater numbers pursued them. This price arbitrage kept prices reasonably similar before centralized, computerized exchanges and data feeds.
As information flow increased, organizations became larger and more effective, and time frames for executing profitable arbitrages decreased. This led traders to develop simple predictive algorithms, like Ed Seykota did, detailed in part 1. New instruments re-opened the profit possibility for a window of time, which eventually closed. The development of futures, options, indexes, all the way to closed exchanges (ICE, etc…) created opportunities for profit which eventually became crowded. Since the actual arbitrages were mathematically complex (futures have an implied interest rate, options require a solution of multiple partial differential equations, and indexes require summing instantaneously hundreds of separate securities) a computational model was necessary as no individual could compute the required elements quickly enough to profit reliably. With this realization, it was only a matter of time before automated trading (AT) happened, and evolved into high-frequency trading with its competing algorithms operating without human oversight on millisecond timeframes.
The journey from daily prices to ever shorter prices over the trading day to millisecond prices was driven by availability of good data and reliable computing which could be counted to act on those flash prices. Once a game of location (geographical arbitrage) turned into a game of speed (competitive pressures on geographical arbitrage) turned into a game of predictive analytics (proprietary trading and trend following) turned into a more complex game of predictive analytics (statistical arbitrage) was then ultimately turned back into a game of speed and location (High frequency trading).
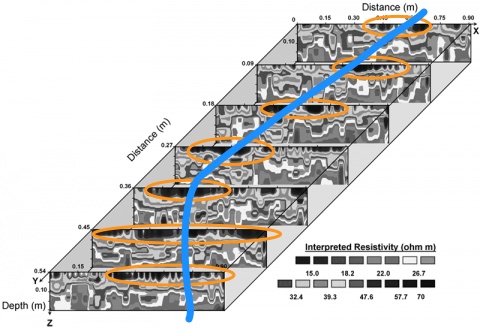
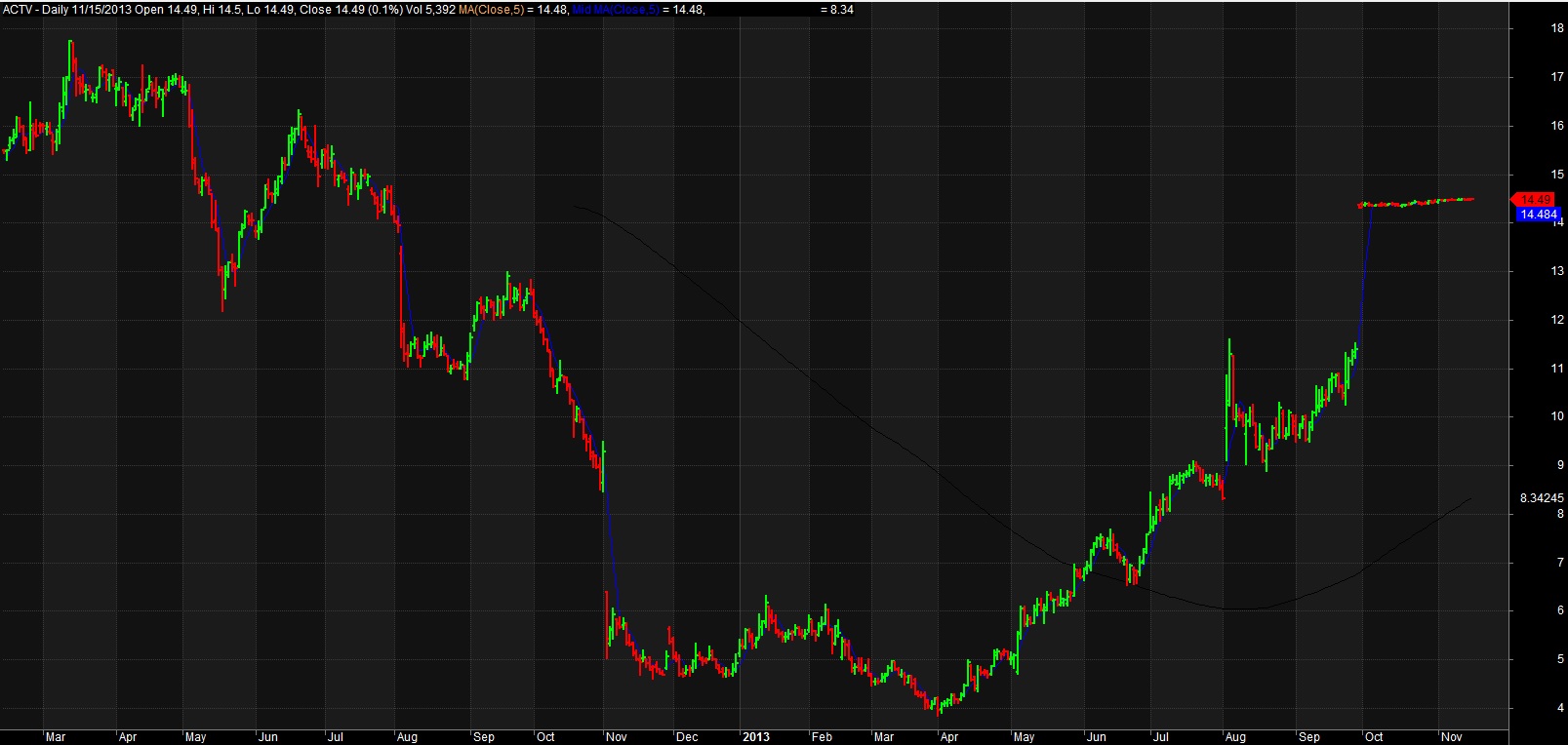
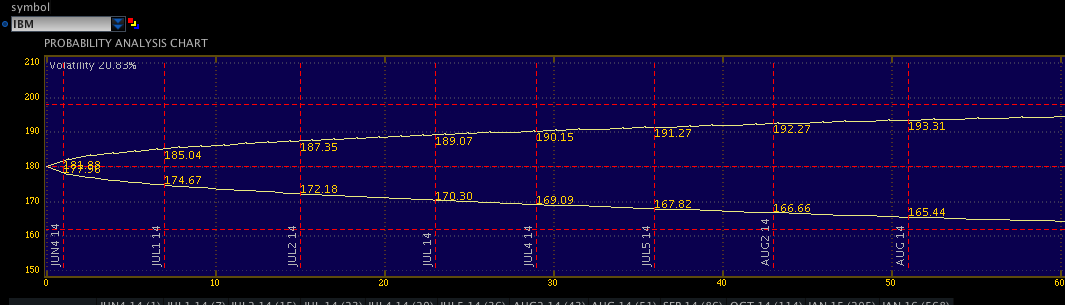
The following chart shows a probability analysis of an ATM straddle position on IBM. This is an options position. It is not important to understand the instrument, only to understand what the image shows. For IBM, the expected variance that exists in price at one standard deviation (+/- 1 s.d.) is plotted in below. As time (days) increases along the X axis, the expected range widens, or becomes less accurate.
Is there a similar corollary for health care?
Yes, but.
First, recognize the distinction between the simpler price-time data which exists in the markets, vs the rich, complex multivariate data in healthcare.
Second, assuming a random walk hypothesis , security price movement is unpredictable, and at best can only be calculated so that the next price will be in a range defined by a number of standard deviations according to one’s model as seen above in the picture. You cannot make this argument in healthcare. This is because the patient’s disease is not a random walk. Disease follows proscribed pathways and natural histories which allow us to make diagnoses and implement treatment options.
It is instructive to consider Clinical Decision Support tools. Please note that these tools are not a substitute for expert medical advice (and my mention does not employ endorsement). See Esagil and diagnosis pro. If you enter “abdominal pain” into either of the algorithms, you’ll get back a list of 23 differentials (woefully incomplete) in Esagil and 739 differentials (more complete, but too many to be of help) in Diagnosis Pro. But this is a typical presentation to a physician – a patient complains of “abdominal pain” and the differential must be narrowed.
At the onset, there is a wide differential diagnosis. The possibility that the pain is a red herring and the patient really has some other, unsuspected, disease must be considered. While there are a good number of diseases with a pathognomonic presentation, uncommon presentations of common diseases are more frequent than common presentations of rare diseases.
In comparison to the trading analogy above, where expected price movement is generally restricted to a quantifiable range based on the observable statistics of the security over a period of time, for a de novo presentation of a patient, this could be anything, and the range of possibilities is quite large.
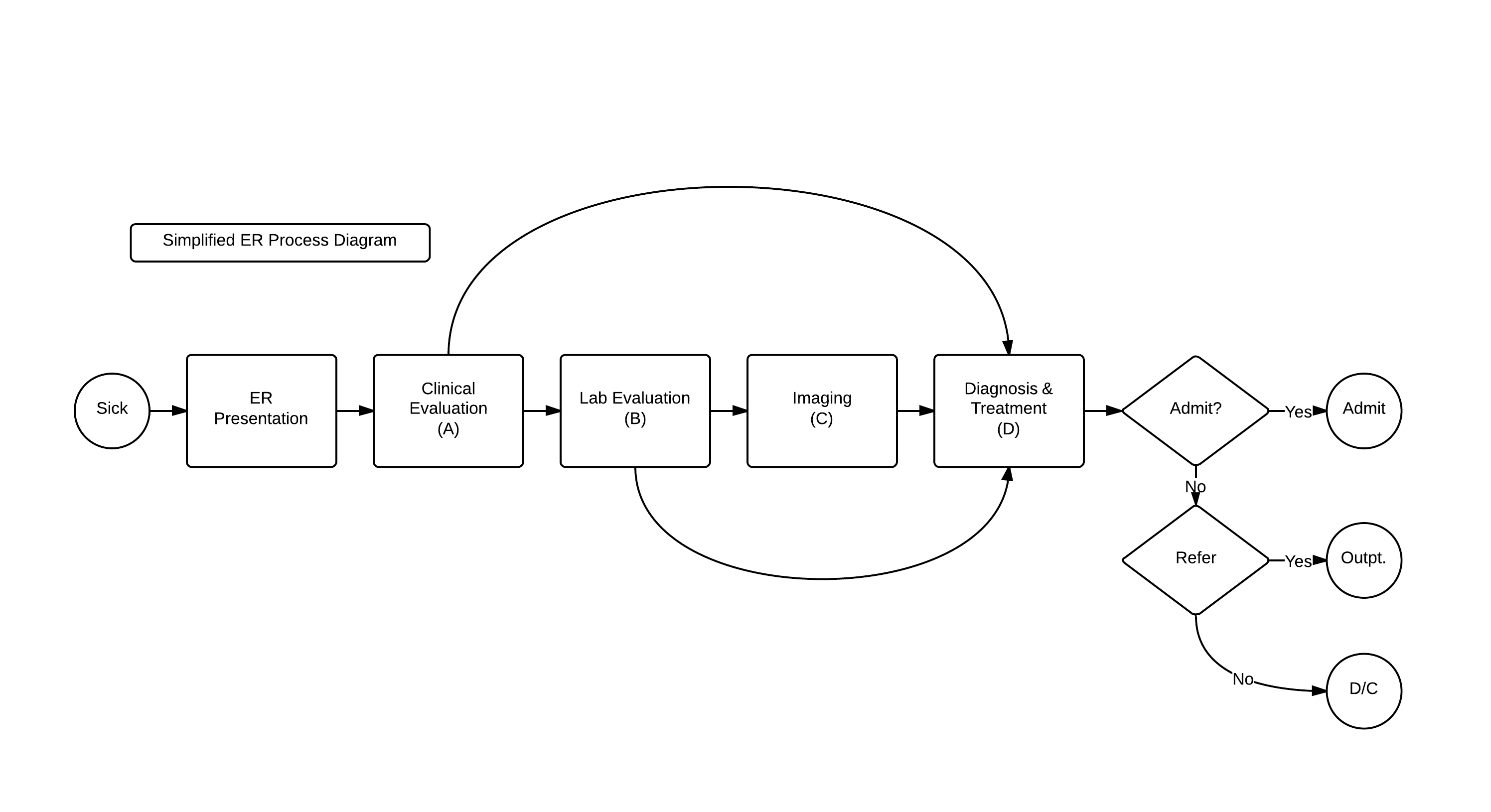
Take, for example, a patient that presents to the ER complaining “I don’t feel well.” When you question them, they tell you that they are having severe chest pain that started an hour and a half ago. That puts you into the acute chest pain diagnostic tree.
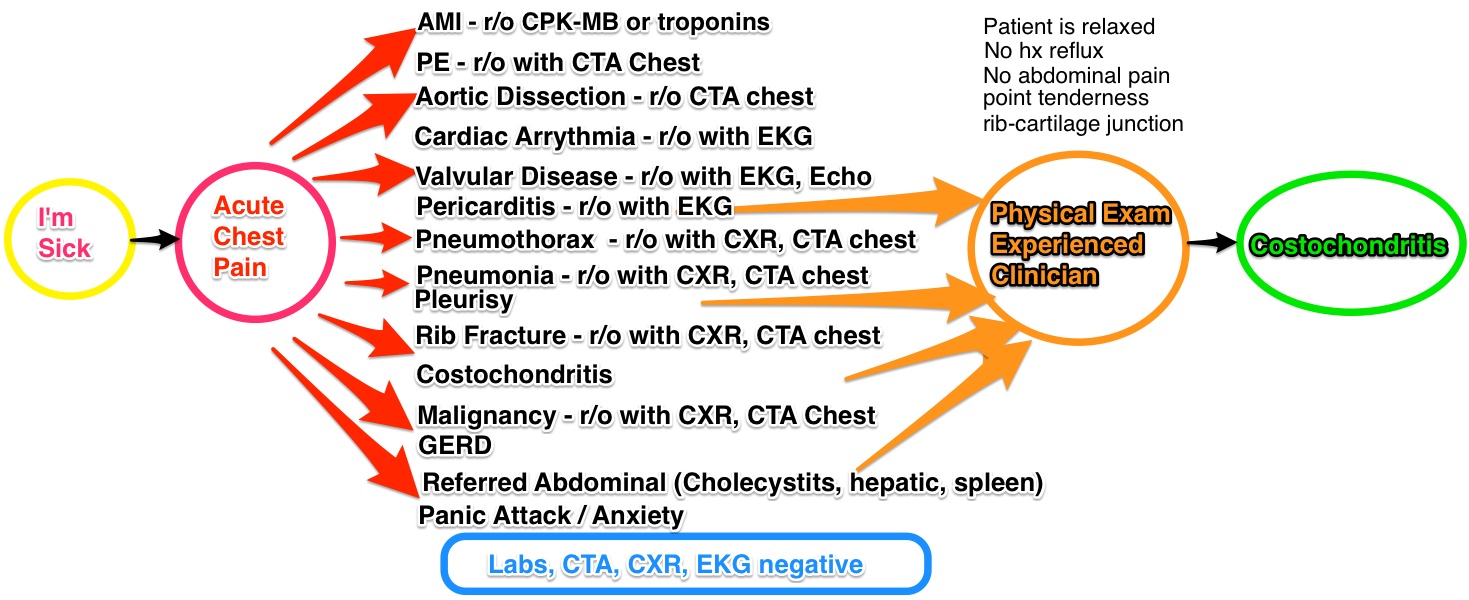
With acute chest pain, there is a list of differentials that needs to be excluded (or ‘ruled out’), some quite serious. A thorough history and physical is done, taking 10-30 minutes. Initial labs are ordered (5-30 minutes if done in a rapid, in-ER test, longer if sent to the main laboratory) an EKG and CXR (chest X-ray) are done for their speed,(10 minutes for each) and the patient is sent to CT for a CTA (CT Angiogram) to rule out a PE (Pulmonary embolism). This is a useful test, because it will not only show the presence or absence of a clot, but will also allow a look at the lungs to exclude pneumonias, effusions, dissections, and malignancies. Estimate that the wait time for the CTA is at least 30 minutes.
The ER doctor then reviews the results (5 minutes)- troponins are negative, excluding a heart attack (MI), the CT scan eliminated PE, Pneumonia, Dissection, Pneumothorax, Effusion, malignancy in the chest. The Chest X-Ray excludes fracture. The normal EKG excludes arrhythmia, gross valvular disease, and pericarditis. The main diagnoses left are GERD, Pleurisy, referred pain, and anxiety. ER doctor goes back to the patient (10 minutes) , patient doesn’t appear anxious & no stressors, so panic attack unlikely. No history of reflux, so GERD unlikely. No abdominal pain component, and labs were negative, so abdominal pathologies unlikely. Point tenderness present on the physical exam at the costochondral junction – and the patient is diagnosed with costochondritis. The patient is then discharged with a prescription for pain control. (30 minutes).
Ok, if you’ve stayed with me, here’s the payoff.
As we proceed down the decision tree, the number of possibilities narrows in medicine.
In comparison, price-time data – in which the range of potential prices increase as you proceed forward in time.
So, in healthcare the potential diagnosis narrows as you proceed down the x-axis of time. Therefore, time is both one’s friend and enemy – friend as it provides for diagnostic and therapeutic interventions which establish the patient’s disease process; enemy as payment models in medicine favor making that diagnostic and treatment process as quick as possible (when a hospital inpatient).
We’ll continue this in part IV and compare it relevance to portfolio trading.
*As an aside, the phones in trading rooms had a switch on the handheld receiver – you would push them in to talk. That way, the other party would not know that you were conducting an arbitrage! They were often slammed down and broken by angry traders – one of the manager’s jobs was to keep a supply of extras in his desk, and they were not hard-wired but plugged in by a jack expressly for that purpose! 
**Yes, for the statisticians reading this, I know that there is an implication of a gaussian distribution that may not be proven. I would suspect the successful houses have modified for this and have instituted non-parametric models as well. Again, this is not a trading, medical or financial advice blog.