
I am an admirer of Nicholas Nassim Taleb – a mercurial options trader who has evolved into a philosopher-mathematician. The focus of his work is on the effects of randomness, how we sometimes mistake randomness for predictable change, and fail to prepare for randomness by excluding outliers in statistics and decision making. These “black swans” arise unpredictably and cause great harm, amplified by systems that have put into place which are ‘fragile’.
Perhaps the best example of a black swan event is the period of financial uncertainty we have lived through during the last decade. A quick recap: the 1998 global financial crisis was caused by a bubble in US real estate assets. This in turn from legislation mandating lower lending standards and facilitating securitization of these loans combining with lower lending standards (subprime, Alt-A) allowed by the proverbial passing of the ‘hot potato’. These mortgages were packaged into derivatives named collateralized debt obligations (CDO’s), using statistical models to gauge default risks in these loans. Loans more likely to default were blended with loans less likely to default, yielding an overall package that was statistically unlikely to default. However, as owners of these securities found out, the statistical models that made them unlikely to default were based on a small sample period in which there were low defaults. The models indicated that the financial crisis was a 25-sigma (standard deviations) event that should only happen once in:
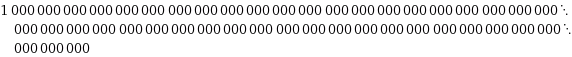 years. (c.f.wolfram alpha)
years. (c.f.wolfram alpha)
Of course, the default events happened in the first five years of their existence, proving that calculation woefully inadequate.
The problem with major black swans is that they are sufficiently rare and impactful enough that it is difficult to plan for them. Global Pandemics, the Fukushima Reactor accident, and the like. By designing robust systems, expecting system perturbations, you can mitigate their effects when they occur and shake off the more frequent minor black (grey) swans – system perturbations that occur occasionally (but more often than you expect); 5-10 sigma events that are not devastating but disruptive (like local disease outbreaks or power outages).
Taleb classifies how things react to randomness into three categories: Fragile, Robust, and Anti-Fragile. While the interested would benefit from reading the original work, here is a brief summary:
1. The Fragile consists of things that hate, or break, from randomness. Think about tightly controlled processes, just-in-time delivery, tightly scheduled areas like the OR when cases are delayed or extended, etc…
2. The Robust consists of things that resist randomness and try not to change. Think about warehousing inventories, overstaffing to mitigate surges in demand, checklists and standard order sets, etc…
3. The Anti-Fragile consists of things that love randomness and improve with serendipity. Think about cross-trained floater employees, serendipitous CEO-employee hallway meetings, lunchroom physician-physician interactions where the patient benefits.
In thinking about Fragile–Robust–Anti-Fragile, be cautious about injecting bias into meaning. After all, we tend to avoid breakable objects, preferring things that are hardy or robust. So, there is a natural tendency to consider fragility ‘bad’, robustness ‘good’ and anti-fragility must be therefore be ‘great!’ Not true – when we approach these categories from an operational or administrative viewpoint.
Fragile processes and systems are those prone to breaking. They hate variation and randomness and respond well to six-sigma analyses and productivity/quality improvement. I believe that fragile systems and processes are those that will benefit the most from automation & technology. Removing human input & interference decreases cycle time and defects. While the fragile may be prone to breaking, that is not necessarily bad. Think of the new entrepreneur’s mantra – ‘fail fast’. Agile/SCRUM development, most common in software (but perhaps useful in Healthcare?) relies on rapid iteration to adapt to a moving target. Fragile systems and processes cannot be avoided – instead they should be highly optimized with the least human involvement. These need careful monitoring (daily? hourly?) to detect failure, at which point a ready team can swoop in, fix whatever has caused the breakage, re-optimize if necessary, and restore the system to functionality. If a fragile process breaks too frequently and causes significant resultant disruption, it probably should be made into a Robust one.
Fragile systems and processes cannot be avoided – instead they should be highly optimized with the least human involvement. These need careful monitoring (daily? hourly?) to detect failure, at which point a ready team can swoop in, fix whatever has caused the breakage, re-optimize if necessary, and restore the system to functionality. If a fragile process breaks too frequently and causes significant resultant disruption, it probably should be made into a Robust one.
Robust systems and processes are those that resist failure due to redundancy and relative waste. These probably are your ‘mission critical’ ones where some variation in the input is expected, but there is a need to produce a standardized output. From time to time your ER is overcome by more patients than available beds, so you create a second holding area for less-acute cases or patients who are waiting transfers/tests. This keeps your ER from shutting down. While it can be wasteful to run this area when the ER is at half-capacity, the waste is tolerable vs. the lost revenue and reputation of patients leaving your ER for your competitor’s ER or the litigation cost of a patient expiring in the ER after waiting 8 hours. The redundant patient histories of physicians, nurses & medical students serve a similar purpose – increasing diagnostic accuracy. Only when additional critical information is volunteered to one but not the other is it a useful practice. Attempting to tightly manage robust processes may either be a waste of time, or turn a robust process into a fragile one by depriving it of sufficient resilience – essentially creating a bottleneck. I suspect that robust processes can be optimized to the first or second sigma – but no more.
Anti-fragile processes and systems benefit from randomness, serendipity, and variability. I believe that many of these are human-centric. The automated process that breaks is fragile, but the team that swoops in to repair it – they’re anti-fragile. The CEO wandering the halls to speak to his or her front-line employees four or five levels down the organizational tree for information – anti-fragile. Clinicians that practice ‘high-touch’ medicine result in good feelings towards the hospital and the unexpected high-upside multi-million dollar bequest of a grateful donor 20 years later – that’s very anti-fragile. It is important to consider that while anti-fragile elements can exist at any level, I suspect that more of them are present at higher-level executive and professional roles in the healthcare delivery environment. It should be considered that automating or tightly managing anti-fragile systems and processes will likely make them LESS productive and efficient. Would the bequest have happened if that physician was tasked and bonused to spend only 5.5 minutes per patient encounter? Six sigma management here will cause the opposite of the desired results.
I think a lot more can be written on this subject, particularly from an operational standpoint. Systems and processes in healthcare can be labeled fragile, robust, or anti-fragile as defined above. Fragile components should have human input reduced to the bare minimum possible, then optimize the heck out of these systems. Expect them to break – but that’s OK – have a plan & team ready for dealing with it, fix it fast, and re-optimize until the next failure. Robust systems should undergo some optimization, and have some resilience or redundancy also built in – and then left the heck alone! Anti-fragile systems should focus on people and great caution should be used in not only optimization, but the metrics used to manage these systems – lest you take an anti-fragile process, force it into a fragile paradigm, and cause failure of that system and process. It is the medical equivalent of forcing a square peg into a round hole. I suspect that when an anti-fragile process fails, this is why.