Quick thought for this Monday morning….
I’m taking Trevor Hastie’s and Robert Tibshirani’s fantastic Statistical Learning course online through Stanford.
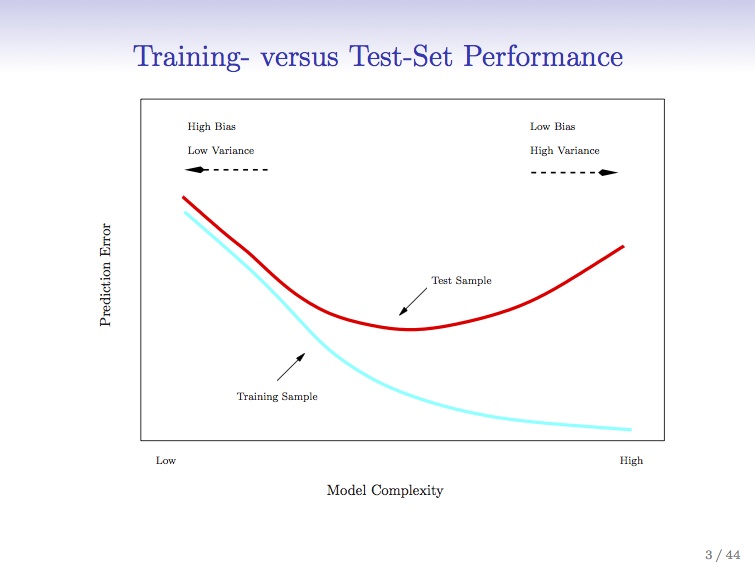
The slide here is great – and shows the danger of complex models and overfitting. For the data scientists – cross validation. If any system traders or finance people are reading, think walk-forward analysis.
Basically, what the graph says is that when you apply a better and better model with higher levels of refinement to your system, you ‘fit’ your established data more accurately. However, because the system is more complex, it is more rigid and less flexible (degrees of freedom, anyone?) and less resilient. Tracks the data better, but works less well in practice. That’s why the red line starts going up again as the scale of complexity goes from low to high. Does this resonate with any of the process improvement (PI) people who are six-sigma trained? Once you scoop up the low-hanging fruit and pass that first or second sigma in iteration, things get tougher. A lot tougher.
This is the trap of curve-fitting (also known as overfitting). More in this case is less, as the model fails to be predictive.
Where I’m going in this blog is to integrate some of these concepts with resource allocation problems in healthcare; and their resulting effect on patient care. I’m particularly interested in applying these techniques to predictive analytics in healthcare. I think we can learn a great deal from the practical applications of these computational statistic tools which have been successfully applied (I know because I started my career doing it) to the markets on Wall St. What medicine can learn from Wall St. is a topic I intend to cover in a series of posts. But healthcare is not the markets, and can’t be approached entirely similarly. The costs of error are catastrophic in terms of lives – it’s not just about money.
I hope you stay with me as I develop this theme.
Image from :https://class.stanford.edu/courses/HumanitiesScience/StatLearning/Winter2014/about
Pingback: What Medicine can learn from Wall Street - part 2 | Volume to Value